程序员经常使用终端,甚至只在终端下工作,那么终端的顺手程度就很重要了。不可避免的,大多数程序员都掌握了配置终端的技巧,但从目前我看到的文章来看,没有比较系统的总结。本文试图通过梳理终端相关的背景知识,整理一个清晰的配置脉络。
我们配置的是终端,还是shell?
通常我们说配置终端的时候,其实隐含的意思是配置shell解释器和终端(terminal),以及常用软件(ls,grep)。为什么这三者都要配置呢?什么配置是属于shell解释器的,什么是由终端软件管理的,什么是软件的配置呢?
想要弄明白这些问题,就需要我们知道他们之间的关系。

shell解释器是terminal进程的一个子进程,shell解释器通过标准输入和标准输出与terminal设备文件交互的,在shell下运行的软件,是shell的子进程,也是通过标准输入输出和terminal设备文件进行交互。值得一提,在类UNIX下,虚拟终端也是一个设备,设备文件形如/dev/ttys。
明白这个关系,我们就知道配置的边界了。比如我想修改一下显示的字体,很显然,shell的标准输出不可能输出字体格式的,我们需要在terminal的配置里找到字体配置需要的字体。
需要注意的是,shell解释器并不特指bash,一台类UNIX操作系统,往往可以支持多种shell解释器。通过
cat /etc/shells可以查看本机支持的shell解释器。另外,不同shell解释器的配置文件也不一样,以bash为例,~/.bash_profile ~/.bashrc是它的配置文件,而zsh则是~/.zsh_profile ~/.zshrc
颜色是怎么显示出来的?
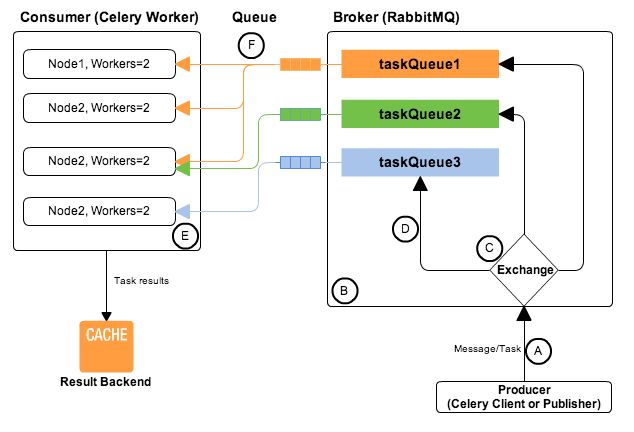
毫无疑问,配置终端的重点在于颜色搭配和语法高亮。既然终端和进程交互是标准输入输出,那标准输出可不可以输出颜色属性呢?
答案是:ANSI转义序列(escape code) 。形如:ESC+[(一般显示为 ^[[)的字符序列可实现在屏幕上定位光标、改变输出字符颜色等功能。例如在bash中, ESC 字符可以用一下三种转义形式输出:
\e\033\x1B
我们可以用”
|
|
终端的显示为:

同理,所谓的终端提示符颜色,以及各种软件结果的输出,只要加上颜色转义,就会被终端显示为对应的颜色。理论上,我们任何的输出都可以自定义颜色,例如下面的方法,将make日志的不同级别分颜色打印出来。
|
|
了解到这些,就明白为什么 ls 指令为什么默认没有颜色,但 ls -G 就有颜色了,输出加入颜色转义了嘛。
我们需要配置终端的什么?
下面我列了下,一般我们需要做的配置清单
字体字号
- 字体:推荐苹果的两代字体 Monaco和Menlo,Monaco第一眼看起来真是惊艳,但普遍反映Menlo更加耐看一点
- 字号:视个人情况而定,个人偏向15号
- 在终端配置文件中修改,以osx为例,终端>偏好设置>描述文件>文本>字体
颜色
终端背景颜色或图片
- 和修改字体一样,在终端配置文件中修改,以osx为例,终端>偏好设置>描述文件>文本>字体
终端颜色支持
这点确实要特别注意,我们使用的终端实际上是伪终端或者叫模拟终端,所以这个软件是可以模拟多种上古终端的,但是不改声明的话,他默认模拟的终端一般都是支持8*2种颜色,那我们其他配置再眼花缭乱也没有,这个终端只能显示16种颜色
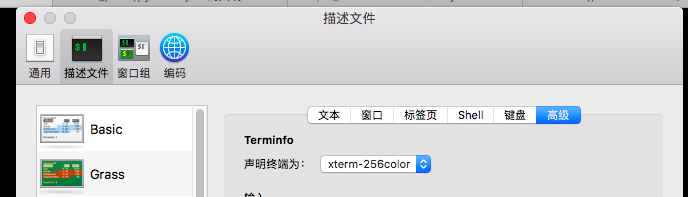
所以这个地方一定要声明为256color的!!!
prompt提示符
prompt提示符是shell解释器的输出,所以需要修改shell解释器配置文件
以bash为例:在~/.bash_profile 中修改PS1环境变量即可。例如:
- 1export PS1="\[\033[36m\]\u\[\033[m\]@\[\033[32m\]\h:\[\033[33;1m\]\w\[\033[m\]\$ "
更详细定制的配置方法网上很多,参见https://linuxconfig.org/bash-prompt-basics
推荐一个可拖动的网站,http://bashrcgenerator.com/
editor(vim,emac)
同理,编辑器的输出设置要在编辑器的配置文件中设置,~/.vimrc中 配置
1colorscheme themevim 自带多种主题可供选择,路径为 /usr/share/vim/vim7x/colors
推荐一个vim的主题网站,http://vimcolors.com/
主题下载后放入~/.vim/colors中,修改vimrc配置即可使用
常用软件(ls, grep, tmux)
- 像ls这种常用软件,颜色格式的输出是有必要的,但是每个软件的配置不太一样,ls需要配置LSCOLORS环境变量,而grep的环境变量是GREP_COLOR
别名
这个根据个人习惯,比较通用的比如
1alias ll="ls -hlF"
但是我只想选择
说了这么多,可能对于很多人来说(比如前段开发),并不需要了解这些,只想用的舒服就好了,有没有简单的方式只要点几下就可以做出一个很完善的终端呢?当然可以…
终端
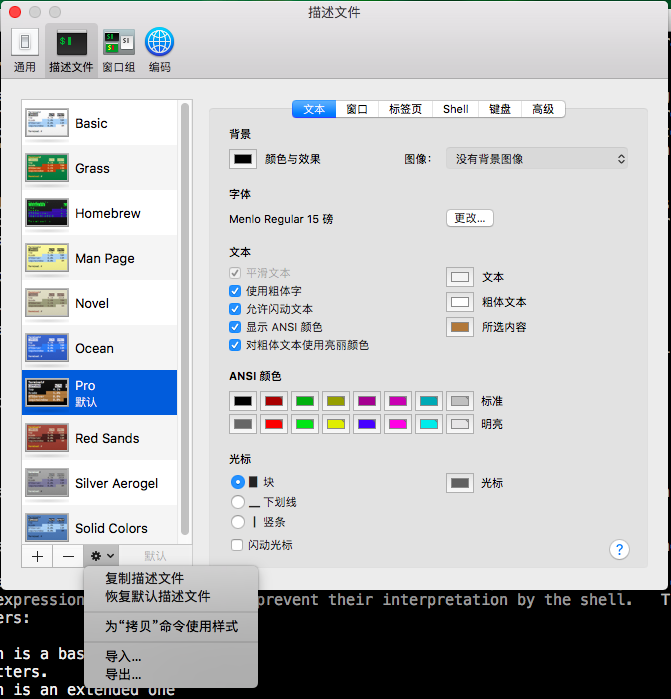
以osx默认终端为例,我们可以看到其实所有配置都在一个叫“描述文件”的选项中,并且,我们可以看到下边的设置,描述文件是可以导出的,那么毫无疑问,github上这些描述文件模板会非常多,总有一款适合你。
详情参见https://github.com/lysyi3m/osx-terminal-themes
见到喜欢的主题,下载后双击或者导入都可以。
iterm2
如果你想体验更多的配置选项,已经更多拓展功能,可以尝试iterm2,个人觉得分屏功能很不错,用了以后会觉得tmux有点鸡肋了。
选择zsh
选择zsh并不是因为zsh从零开始配置比bash容易很多,而是因为zsh的插件系统,导致网上有很多可供选择的模板,让我们轻松定制。比如
- oh-my-zsh, https://github.com/robbyrussell/oh-my-zsh 只要运行一行安装指令,什么语法高亮,自动补全,不同软件甚至git的配置统统都有了,非常强大。
- Prezto,https://github.com/sorin-ionescu/prezto 如果你觉得oh-my-zsh功能太多,并且有点卡或者有点慢了,可以试试Prezto,这个可以认为是一个速度更快的oh-my-zsh,但是缺陷是插件没有oh-my-zsh多。