介绍一下背景
最近项目中有一个接口,是通过redis队列做的。我将对方需要的数据通过json 字符串的形式,push到redis list队列中,对方监听并消费(题外话, 我对这种形式的交互有点看法吧,双方既然是接口,但是很难保证格式的统一,比使用rpc框架强验证风险大的多)。
由于对端也是用python做的消费者,所以也是相安无事。随着一个需求的变更,我在自己调试pop的数据发现,我写的json字符串是,酱事儿的:
当时我就懵逼了,这是什么鬼…
很显然这个是unicode字符串嘛,但是我明明就编码成了UTF8啦,怎么最后是这个鬼样子,更奇怪的是对方能正确解码吗?这明明是四不像啊。
我试着自己重现了整个过程。
首先,我将utf8形式的字符串 我爱北京天安门 dumps成json:
果然,确实变成了这个样子,看来是json库搞得鬼。
先不管他,看看这个结果load出来什么样子:
确实load没问题,但是可以看到,最后的结果和我当时dumps的出入蛮大的,由原来的utf8 str形式,变为了unicode形式,就连字典的key也都是unicode了。
好吧,所以现在就有了两个问题。
- 为什么utf8字符串, json dumps后不是原来形式?
- 为什么loads回来的数据全是unicode形式?
为什么utf8字符串, json dumps后不是原来形式?
看下官方文档: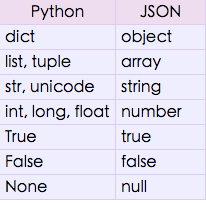
json.dumps方法做的就是将python数据格式按照上图的映射方式转换为json格式。Python str和unicode都可以转换成json 的string形式,我们知道str和unicode差别很大啊,如果一个python字典中,同时有str和unicode的时候,json dump怎么处理呢?试一下:
没有异常,并且都是最后按照unicode的方式统一处理的。看来python是先将str decode为unicode,然后再用unicode进行编码的。
这样本来无可厚非,自己统一好编码格式就行了,loads的时候按照编码的方式,反过来解码。但是问题是,和我们进行交互的人未必也用的python啊,当他用其他的语言对json解码的时候,还原回来就是一堆乱码了,我们能不能让json库,确实编码成utf8形式呢?
官方文档如是说:
If ensure_ascii is True (the default), all non-ASCII characters in the output are escaped with \uXXXX sequences, and the results are str instances consisting of ASCII characters only. If ensure_ascii is False, a result may be a unicode instance. This usually happens if the input contains unicode strings or the encoding parameter is used.
看来是 ensure_ascii 参数为 True 的时候,确保了所有非ASCII字符都转义成 \uXXXX 的ASCII序列。
如果我们设置为False,就可以还原本来面目了吗?试试:
果然哦,我们干脆看看python json库源码怎么实现的吧, 主要就是下列这个判断
|
|
既然ensure_ascii = False时, 没有做类型的转换,所以我们原来是什么,编码后就是什么。但这带来了以下副作用:
如果我们要转换的python数据类型,如果既包含str又包含unicode,在连接字符串的时候肯定会抛出编码异常
12In [13]: json.dumps({"title_str":"我爱北京天安门", "title_unicode":u"我爱北京天安门"}, ensure_ascii=False)"UnicodeDecodeError: 'ascii' codec can't decode byte 0xe6 in position 1: ordinal not in range(128)"如果全部都是unicode进行字符串连接,返回值也是unicode
12In [3]: json.dumps({"title_str":u"我爱北京天安门", "title":u"我爱世界"}, ensure_ascii=False)Out[3]: u'{"title": "\u6211\u7231\u4e16\u754c", "title_str": "\u6211\u7231\u5317\u4eac\u5929\u5b89\u95e8"}'如果全部都是str进行字符串连接,返回值也是str
12In [2]: json.dumps({"title_str":"我爱北京天安门", "title":"我爱世界"}, ensure_ascii=False)Out[2]: '{"title": "\xe6\x88\x91\xe7\x88\xb1\xe4\xb8\x96\xe7\x95\x8c", "title_str": "\xe6\x88\x91\xe7\x88\xb1\xe5\x8c\x97\xe4\xba\xac\xe5\xa4\xa9\xe5\xae\x89\xe9\x97\xa8"}'
为了能将json字符串通用的和其他语言交换,我们不得不保证,原始python数据类型必须是统一的。要么全是UTF8的str类型,要么全部是unicode,最后在encode为utf8, 否则就会有异常 这个也是动态类型要付出的代价吧。
为什么loads回来的数据全是unicode形式?
看下官方文档: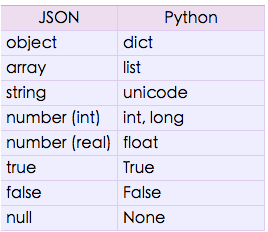
与dumps相反, json.loads 方法做的就是将json数据格式按照上图的映射方式转换为python类型。我们可以看json string 转换回来只有一种格式,那就是unicode,这样就能解释我们看到的现象了,就连dict key都是unicode的。
好麻烦啊,怎么根本的解决这个问题呢?
答: 使用python3