两年前,公司所有的管理后台用的都是django admin,我们遇到一个复杂的需求,需要从django admin调用执行一个大批量处理脚本,并且可以查看执行状态。
当时不太了解celery,加上时间紧迫,就没敢冒险。简单说说我们当时是怎么做的,我们把这个脚本做成了command line的形式,django使用python的subprocess调用这个命令,为了满足可以查看状态这个需求,我们单独创建了一个任务表,在启动脚本时先插入数据,完成或者异常都更新这条数据状态,这样在django admin里就能看到执行状态了。
这个方法满足了需求,并沿用到现在,但是这里有一个显而易见的硬伤:django必须和这个脚本在同一个服务器上。好吧,毫无可拓展性。
其实这个就是一个天然celery使用场景,如果使用celery就可以轻松解决分布拓展问题。
什么是celery?
说了这么多,什么是celery呢?官网定义:
Celery is an asynchronous task queue/job queue based on distributed message passing.
celery是一个基于分布消息传递的异步任务队列。定义很简单,但是这里隐含了一个条件就是celery不是单独存在的,它一定需要建立在一个分布的消息传递机制上,这个消息传递机制就是celery文档里常说的broker。我认为这是第一个难以理解的点。
一般情况下,一个工具库或者一个框架都是独立的,有自己的feature或者功能点,可能依赖其他的库,但绝不依赖于其他服务。但是celery是一个特例,如果celery没有broker这个服务,那就完全不能用了。这就是为什么现在网络上大多数celery文章都是和rabbitmq或者redis一起讲的。
清楚这点,知道了broker和celery的关系,就不会有rabbitmq不就可以做任务队列吗?为什么和celery结合?这样的疑问。事实上,在官网上就有使用rabbit作为任务队列的实现,多种语言都有。rabbitmq是消息代理中间件,具体应用到什么场景,怎么用,用什么语言,都可以自己定义,celery也实现了这个接口而已。
celery结构框架
下面贴一个celery+rabbitmq的结构图,个人认为挺能说明问题: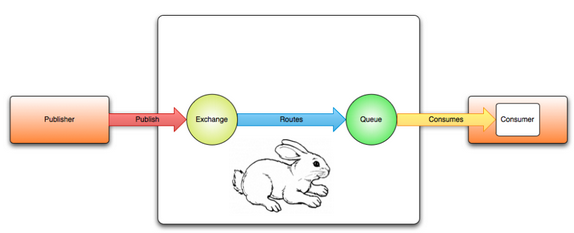
celery隐藏了rabbitmq接口的实现细节,既充当了publisher(client)又充当了consumer (worker)的角色。
这是第二个难理解的点,这个困扰可能来源于celery提供的get start文档,如果按照这个文档一步步走,确实能走通流程。但是这个通俗的demo有一个问题,就是他的publisher和consumer都在一台server上,并且client调用具体任务的方式是通过import。这让人很难理解,为什么说celery是分布的呢?但是奇怪的是,官方demo就没有publisher和consumer分布在两台server的例子。
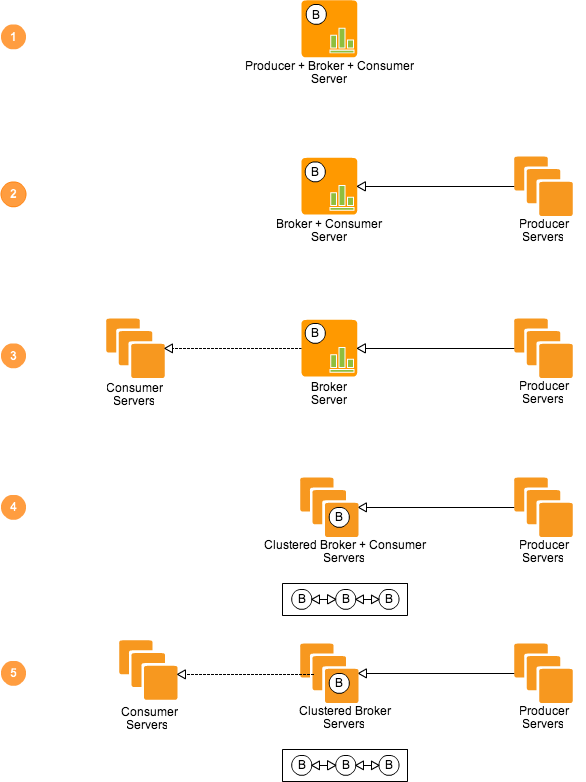
如上图所示,producer、broker、consumer之间的网络拓扑关系可以有这5种情形。
celery到底做了什么?
上文说了,rabbitmq官网就有demo做任务队列的,那要celery有何用呢?还有上边,我提到的那个需求,没用celery,虽然拓展性不好,但是改一下用一个web服务代替不就行了么?这么说没错,但都是重复造轮子。
思考一下,如果我们用rabbitmq自己实现任务队列,有一天我们不想用rabbit了怎么办?我们换个思维,如果没有celery,让你自己设计一个异步任务队列你怎么做。首先,要有一个发起任务的client,选定一定保存任务信息的媒介,由一个worker去一直监听这个信息媒介,这个worker最好是多进程的,另外可以兼容尽可能多得信息媒介。好吧,这个不就是celery所做的事儿么,celery兼容多个broker,既是任务发起者又是执行者,另外支持多进程…还有好多通用功能考虑。
看一下这个图体会一下celery+rabbitmq的整个工作流程:
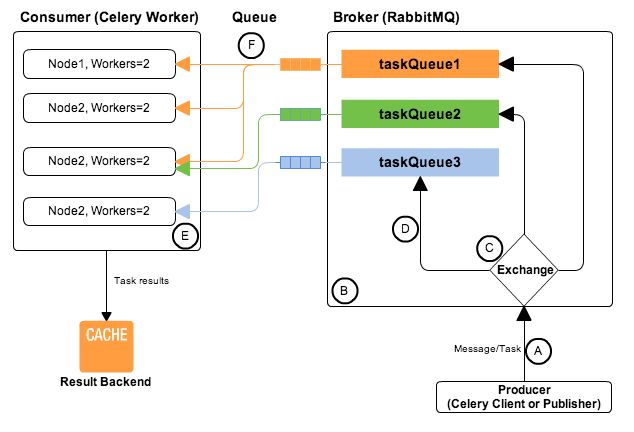
我是怎么用的?
说了这么多,来看看我是怎么用的。
选择broker和result backend
知道了原理,这个选择要容易些,对于消息中转,没有比rabbitmq更灵活健壮的了,至于对result backend的存储,仁者见仁。rabbitmq安装配置参考提取celery配置文件
把共有配置文件提出来,进行维护,比分别维护producer和consumer的配置统一容易的多。
celeryconfig.py12345BROKER_URL = 'amqp://test01:password@192.10.2.156//'CELERY_RESULT_BACKEND = 'amqp://test01:password@192.10.2.156//'CELERY_ACCEPT_CONTENT = ['json']CELERY_TASK_SERIALIZER = 'json'CELERY_RESULT_SERIALIZER = 'json'consumer(server)端开发
在项目目录下创建app.py文件
12345from celery import Celeryapp = Celery('tqlib', include=['tq.tasks'])app.config_from_object('celeryconfig')if __name__ == '__main__':app.start()创建tasks.py
1234from tq.app import appdef test(no):print no启动多进程服务
项目目录结构为tq----app.py |---tasks.py |---celeryconfig.py启动指令为:
1celery multi restart ccworker --app=tq.app -l
producer(client)端开发
1234from celery import Celerycelery = Celery()celery.config_from_object('celeryconfig')celery.send_task('tq.tasks.test', ("hello world",))注意,就是celery.send_task()这个方法解决了producer和consumer的网路拓扑传递数据问题。